
In the latest MLPerf Inference v5.0 results, NVIDIA has once again established itself as a leader in AI inference performance. The benchmark results highlight significant advances in speed and efficiency, particularly with the debut of the NVIDIA GB200 NVL72 system — a rack-scale platform designed to meet the growing demands of AI factories.
AI factories, unlike traditional data centres, are engineered to transform raw data into real-time intelligence. They rely heavily on advanced infrastructure to process massive and complex AI models, which often contain billions or even trillions of parameters. These increasingly sophisticated models raise the computational demands and cost per token, making it essential to optimise across the entire tech stack — from hardware and networking to software.
GB200 NVL72 delivers unmatched performance on large language models
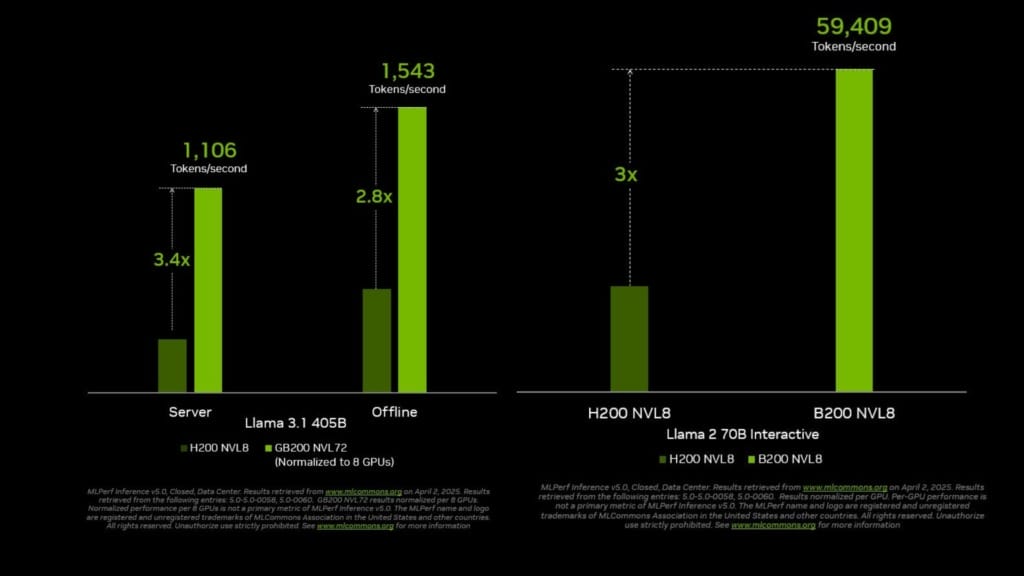
The GB200 NVL72 system connects 72 Blackwell GPUs into a unified massive GPU, delivering up to 30 times the token throughput on the new Llama 3.1 405B benchmark compared to the previous H200 NVL8 configuration. This performance gain is driven by more than triple the performance per GPU and a ninefold increase in NVLink domain size. Notably, NVIDIA and its partners were the only ones to submit results for the Llama 3.1 405B benchmark, underlining the company’s leadership in tackling the most demanding inference workloads.
In real-world AI applications, two key latency metrics affect user experience: time to first token (TTFT) and time per output token (TPOT). To better reflect these constraints, the Llama 2 70B Interactive benchmark was introduced, requiring five times faster TPOT and 4.4 times lower TTFT than the original. On this more stringent benchmark, a DGX B200 system powered by eight Blackwell GPUs achieved triple the performance of a system using eight H200 GPUs.
These achievements show how the Blackwell platform, combined with NVIDIA’s full software stack, can dramatically boost inference performance. This not only enables faster AI responses but also supports higher throughput and more cost-effective deployments for AI factories.
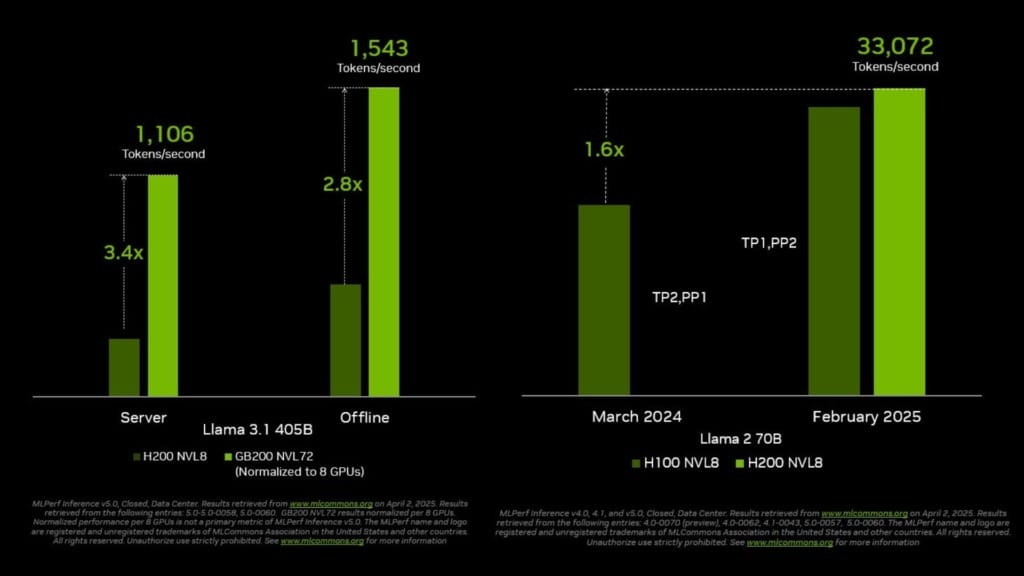
Hopper platform continues to show growth and versatility
While Blackwell took centre stage, NVIDIA’s Hopper architecture also showed strong results in this round of testing. Since the release of MLPerf Inference v4.0 a year ago, H100 GPU throughput on the Llama 2 70B benchmark has increased by 1.5 times. The H200 GPU, which builds on Hopper with expanded and faster memory, raised this further to 1.6 times. Hopper successfully ran every test in the benchmark suite, including the new Llama 3.1 405B and Llama 2 70B Interactive models, demonstrating its flexibility and relevance for a broad range of workloads.
One standout result came from a B200-based system achieving over 59,000 tokens per second on the Llama 2 70B Interactive benchmark — tripling the throughput of the H200 configuration. Similarly, on the Llama 3.1 405B test, the GB200 NVL72 system pushed performance up to 13,886 tokens per second, marking a 30x increase compared to previous results.
AI ecosystem support and inference software advances
This round of MLPerf testing saw participation from 15 NVIDIA partners, including major industry names like ASUS, Dell Technologies, Google Cloud, Lenovo, and Oracle Cloud Infrastructure. These wide-ranging submissions reflect the availability and scalability of the NVIDIA platform across global server manufacturers and cloud providers.
NVIDIA also highlighted the role of its AI inference software, including the new NVIDIA Dynamo platform. Dynamo serves as an “operating system” for AI factories, offering smart routing, GPU planning, and KV-cache offloading for large-scale inference operations. The software enables innovations such as disaggregated serving — separating the prefill and decode stages of model execution — which allows for independent optimisation of performance and cost.
With tools like TensorRT-LLM and support for DeepSeek-R1 models, NVIDIA continues to expand inference capabilities without compromising accuracy. A notable result was the successful deployment of the first FP4 DeepSeek-R1 model on the DGX B200, which achieved high performance and accuracy with over 250 TPS per user at low latency.
NVIDIA’s continued dominance in MLPerf benchmarks underscores its focus on delivering full-stack AI performance. As larger models become the norm, and the need for high-speed, cost-efficient inference rises, NVIDIA’s Blackwell and Hopper platforms, backed by a strong partner ecosystem, are set to power the next generation of AI factories worldwide.




{kind=link}